Computer Vision
AI
این مقاله به بررسی جامع پیشرفتهای اخیر در حوزه بینایی کامپیوتری (Computer Vision) میپردازد. در سالهای اخیر، با ظهور معماریهای عمیق یادگیری ماشین مانند شبکههای عصبی کانولوشنی (CNNs) و انواع مدلهای Transformer، تحولی اساسی در این حوزه رخ داده است. این مقاله ضمن تشریح دستاوردهای مهم، به چالشهای موجود و راههای پیش رو میپردازد و افقهای آینده را مورد بحث قرار میدهد.
بینایی کامپیوتری به عنوان شاخهای از هوش مصنوعی، به توانایی کامپیوترها در درک و تفسیر محتوای تصاویر و ویدئوها اشاره دارد. این علم تلاش میکند تا سیستمهایی را طراحی کند که بتوانند همانند انسان، محیط اطراف خود را با استفاده از دوربینها و سنسورها مشاهده، تحلیل و درک کنند. از زمان پیدایش تا امروز، بینایی کامپیوتری از Algorithmهای ساده تشخیص لبه و شکل به سیستمهای پیچیدهای تکامل یافته که قادر به شناسایی اشیاء (Identifying Objects)، تشخیص چهره (Facial Recognition)، ردیابی حرکت (Motion Tracking)، بازسازی سهبعدی و حتی درک معنایی صحنه هستند.

1- اهمیت بینایی کامپیوتری
در عصر دیجیتال کنونی، بینایی کامپیوتری نقش محوری در انقلاب صنعتی چهارم و هوشمند سازی فرآیندها ایفاء میکند. این حوزه در تحول صنایع مختلف از جمله خودروهای خودران، پزشکی، امنیت، رباتیک واقعیت افزوده و اینترنت اشیاء نقش اساسی دارد. توانایی ماشینها در درک و پردازش دادههای تصویری، مرزهای جدیدی از خودکار سازی و هوشمند سازی را گشوده است.
2- پیشرفتهای معمارانه در بینایی کامپیوتری
۲.۱- از CNN تا Transformer
تا قبل از سال ۲۰۱۲، پیشرفتهای بینایی کامپیوتری عمدتاً بر پایه روشهای دستی استخراج ویژگی (Hand-Crafted Features) مانند SIFT, HOG و LBP استوار بود. نقطه عطف اصلی با معرفی AlexNet در مسابقه ImageNet 2012 اتفاق افتاد که با استفاده از شبکه عصبی کانولوشنی عمیق (Deep CNN) خطای طبقهبندی تصاویر را به طور چشمگیری کاهش داد. پس از آن، معماریهای مختلف CNN مانند VGG, GoogLeNet (Inception), ResNetو DenseNet با معرفی تکنیکهای مختلف مانند اتصالات باقیمانده (Residual Connections) و اتصالات متراکم (Dense Connections) برای حل مشکل گرادیان محو شونده (Vanishing Gradient) و بهبود یادگیری عمیق توسعه یافتند. در سالهای اخیر، معماری Transformer که ابتدا برای پردازش زبان طبیعی معرفی شد، با ارائه ViT (Vision Transformer) و سایر Variantها به حوزه بینایی کامپیوتری راه یافت. مکانیزم خود توجهی (Self- Attention) در این معماریها امکان مدل سازی روابط طولانی مدت بین Pixelها و قسمتهای مختلف تصویر را فراهم کرده است.
۲.۲- Multimodal Models
پیشرفت دیگر در این حوزه، ظهور مدلهای چند مودالیتی (Multimodal Models) مانند CLIP, DALL-E و Stable Diffusion است که قادر به پردازش همزمان متن و تصویر هستند. این مدلها توانستهاند درک معنایی عمیقتری از تصاویر ایجاد کنند و کاربردهای جدیدی مانند تولید تصویر از متن را ممکن سازند.
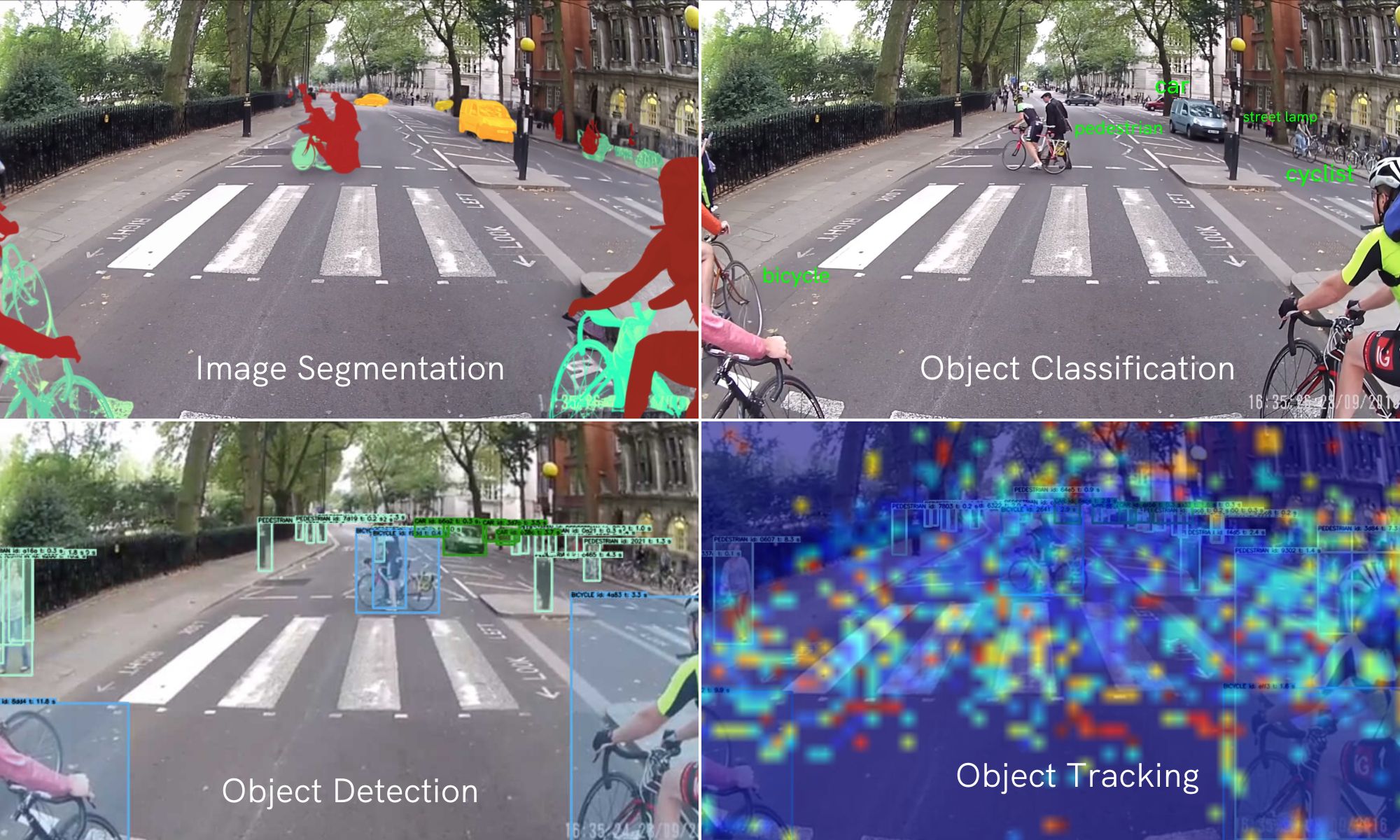
3- حوزههای کلیدی تحقیق و کاربرد
۳.۱- تشخیص و طبقهبندی اشیاء
تشخیص اشیاء یکی از پایهایترین وظایف در بینایی کامپیوتری است. مدلهای One-Stage مانند YOLO و SSD در مقابل مدلهای Two-Stage مانند Faster R-CNN، تعادلی بین سرعت و دقت ارائه میدهند. نسلهای جدید این مدلها مانند YOLOv8 و DETR (Detection Transformer) توانستهاند دقتهای بالاتر و کارایی بهتری را ارائه دهند.
۳.۲- Semantic Segmentation و Instance Segmentation
Segmentation یا قطعهبندی تصاویر به دو دسته اصلی تقسیم میشود: Semantic Segmentation که هر پیکسل را به یک کلاس نسبت میدهد و Instance Segmentation که علاوه بر آن، نمونههای مختلف از یک کلاس را تفکیک میکند. معماریهای کلیدی در این حوزه شامل U-Net, Mask R-CNN و Segment Anything Model (SAM) هستند که اخیراً توسط Meta معرفی شده و قابلیتهای فوق العادهای در Segmentation با کمترین نظارت نشان داده است.
۳.۳- تخمین پز و ردیابی حرکت
تخمین پز انسان (Human Pose Estimation) و ردیابی اشیاء متحرک از دیگر زمینههای پررشد بینایی کامپیوتری هستند. روشهای مبتنی بر گراف مانند Graph CNN و روشهای مبتنی بر بازنمایی (Heatmap Representation) مانند HRNet از جمله پیشرفتهای کلیدی در این زمینه هستند. این تکنیکها کاربردهای گستردهای در تحلیل حرکات ورزشی، تعامل انسان-کامپیوتر و سیستمهای نظارتی دارند.
۳.۴- بازسازی 3D و Neural Encoding
بازسازی سهبعدی از تصاویر دوبعدی همواره چالشی بزرگ در بینایی کامپیوتری بوده است. اخیراً با معرفی روشهایی مانند Neural Radiance Fields (NeRF) و Neural Encoding، امکان بازسازی بسیار دقیق صحنههای پیچیده سهبعدی از مجموعهای از تصاویر دوبعدی فراهم شده است. این روشها در صنایعی مانند بازیسازی، معماری و واقعیت مجازی کاربردهای گستردهای دارند.
4- چالشهای فعلی و راهکارها
۴.۱- یادگیری با حداقل دادههای برچسب خورده
یکی از چالشهای اصلی در حوزه بینایی کامپیوتری، نیاز به حجم بالای دادههای برچسب خورده برای آموزش مدلهای عمیق است. راهکارهای مختلفی برای غلبه بر این چالش ارائه شده است:
- یادگیری خودنظارتی (Self-Supervised Learning): روشهایی مانند MoCo, SimCLR و DINO با طراحی وظایف پیش آموزشی (Pretext Tasks) مانند پیشبینی چرخش تصویر یا بازسازی قسمتهای حذف شده، امکان یادگیری بازنماییهای مفید بدون نیاز به برچسب را فراهم میکنند.
- یادگیری انتقالی (Transfer Learning): استفاده از مدلهای پیش آموزش دیده روی مجموعه دادههای بزرگ و سپس تنظیم دقیق آنها برای وظایف خاص با دادههای محدود.
- یادگیری فدرال (Federated Learning): آموزش مدلها روی دادههای پراکنده در دستگاههای مختلف بدون نیاز به جمعآوری متمرکز دادهها، که به حفظ حریم خصوصی نیز کمک میکند.
۴.۲- قابلیت تعمیم و مقاومت در برابر حملات
مدلهای بینایی کامپیوتری اغلب در مواجهه با دادههای خارج از توزیع آموزشی دچار افت عملکرد میشوند. همچنین، این مدلها در برابر حملات خصمانه (Adversarial Attacks) آسیبپذیر هستند. برای بهبود قابلیت تعمیم و مقاومت، راهکارهایی مانند تنظیم سازی قوی (Robust Regularization)، آموزش با دادههای تقویت شده (Data Augmentation) و دفاع فعال (Active Defense) مورد تحقیق قرار گرفتهاند.
۴.۳- تفسیرپذیری و اخلاق در بینایی کامپیوتری
با گسترش کاربرد بینایی کامپیوتری در تصمیم گیریهای حساس مانند تشخیص پزشکی و سیستمهای نظارتی، نیاز به تفسیرپذیری مدلها و رعایت اصول اخلاقی بیش از پیش احساس میشود. تکنیکهایی مانند Grad-CAM و LIME برای تفسیر تصمیمات مدلها توسعه یافتهاند، اما همچنان فاصله زیادی تا دستیابی به شفافیت کامل وجود دارد.
۴.۴- کارایی محاسباتی و پیادهسازی در دستگاههای محدود
بسیاری از مدلهای قدرتمند بینایی کامپیوتری نیازمند منابع محاسباتی سنگین هستند که پیادهسازی آنها در دستگاههای محدود مانند تلفنهای هوشمند و سیستمهای تعبیه شده را دشوار میسازد. تکنیکهای فشردهسازی مدل مانند هرس کردن (Pruning)، کوانتیزاسیون (Quantization) و تقطیر دانش (Knowledge Distillation) برای حل این چالش ارائه شدهاند.
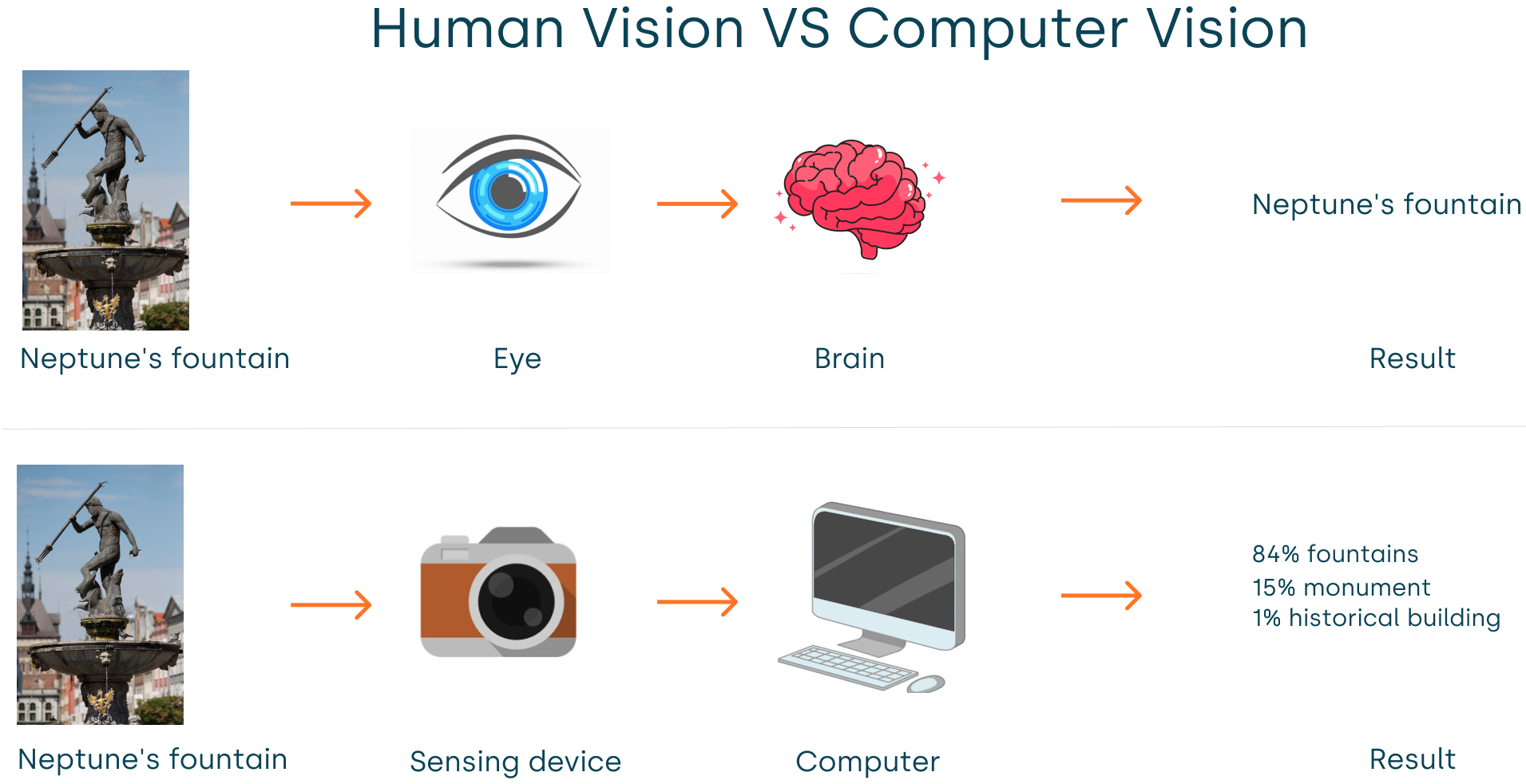
5- آینده بینایی کامپیوتری
۵.۱- یکپارچهسازی با سایر حوزههای هوش مصنوعی
آینده بینایی کامپیوتری در گرو یکپارچهسازی عمیقتر با سایر حوزههای هوش مصنوعی مانند پردازش زبان طبیعی، یادگیری تقویتی و استدلال نمادین است. مدلهای یکپارچه مانند GPT-4V و Gemini که قادر به پردازش و درک همزمان تصویر و متن هستند، نمونههای اولیه از این روند هستند.
۵.۲- بینایی کامپیوتری پویا و وابسته به زمان
بیشتر تحقیقات فعلی در بینایی کامپیوتری بر روی تصاویر ثابت متمرکز است، اما آینده این حوزه به سمت درک عمیقتر دنبالههای ویدئویی و تحلیل رویدادها در طول زمان پیش میرود. مدلهای مبتنی بر حافظه (Memory-Based Models) و شبکههای عصبی بازگشتی پیشرفته (Advanced RNNs) میتوانند به درک بهتر زمینه و روابط زمانی کمک کنند.
۵.۳- سیستمهای هوشمند با قابلیت یاد گیری مداوم
سیستمهای بینایی کامپیوتری آینده باید قادر به یادگیری مداوم از تجربیات خود باشند، بدون آنکه دچار فراموشی فاجعه بار (Catastrophic Forgetting) شوند. روشهای یادگیری افزایشی (Incremental Learning) و معماریهای مبتنی بر حافظه گسترش یافته (Expanded Memory Architectures) از جمله راهکارهای امیدبخش در این زمینه هستند.
۵.۴- بینایی کامپیوتری عصبی - نمادین
ترکیب رویکردهای یادگیری عمیق با استدلال نمادین میتواند به سیستمهای بینایی کامپیوتری کمک کند تا علاوه بر تشخیص الگوها، قادر به استدلال در مورد روابط علت و معلولی و انتزاع مفاهیم از تصاویر باشند. این ترکیب میتواند به مدلهایی با قابلیت تعمیم بهتر و نیاز به دادههای آموزشی کمتر منجر شود.
نتیجهگیری
بینایی کامپیوتری در دهه گذشته پیشرفتهای خیره کنندهای داشته و از مرحله تحقیقات آکادمیک به کاربردهای واقعی و گسترده در صنعت رسیده است. با این حال، چالشهای مهمی همچنان پیش روی این حوزه قرار دارد. پیشرفتهای آینده در این زمینه نه تنها به توسعه معماریهای جدید، بلکه به رویکردهای میانرشتهای و تلفیق دانش از حوزههای مختلف وابسته است. مسیر آینده بینایی کامپیوتری به سمت سیستمهایی است که همانند انسان، قادر به درک عمیق محتوای بصری، استنتاج روابط معنایی و ایجاد بازنماییهای انتزاعی از جهان اطراف باشند. با توجه به روند فعلی پیشرفتها، میتوان انتظار داشت که در آینده نزدیک، سیستمهای بینایی کامپیوتری به عنوان بخشی جدایی ناپذیر از زندگی روزمره و صنایع مختلف، نقش پررنگتری ایفاء کنند.
منابع:
- Kirillov, A., et al. (2023). Segment Anything. arXiv preprint arXiv:2304.02643.
- OpenAI. (2023). GPT-4V System Card. OpenAI Technical Report.