ارائه سرویس دهی بدون وقفه
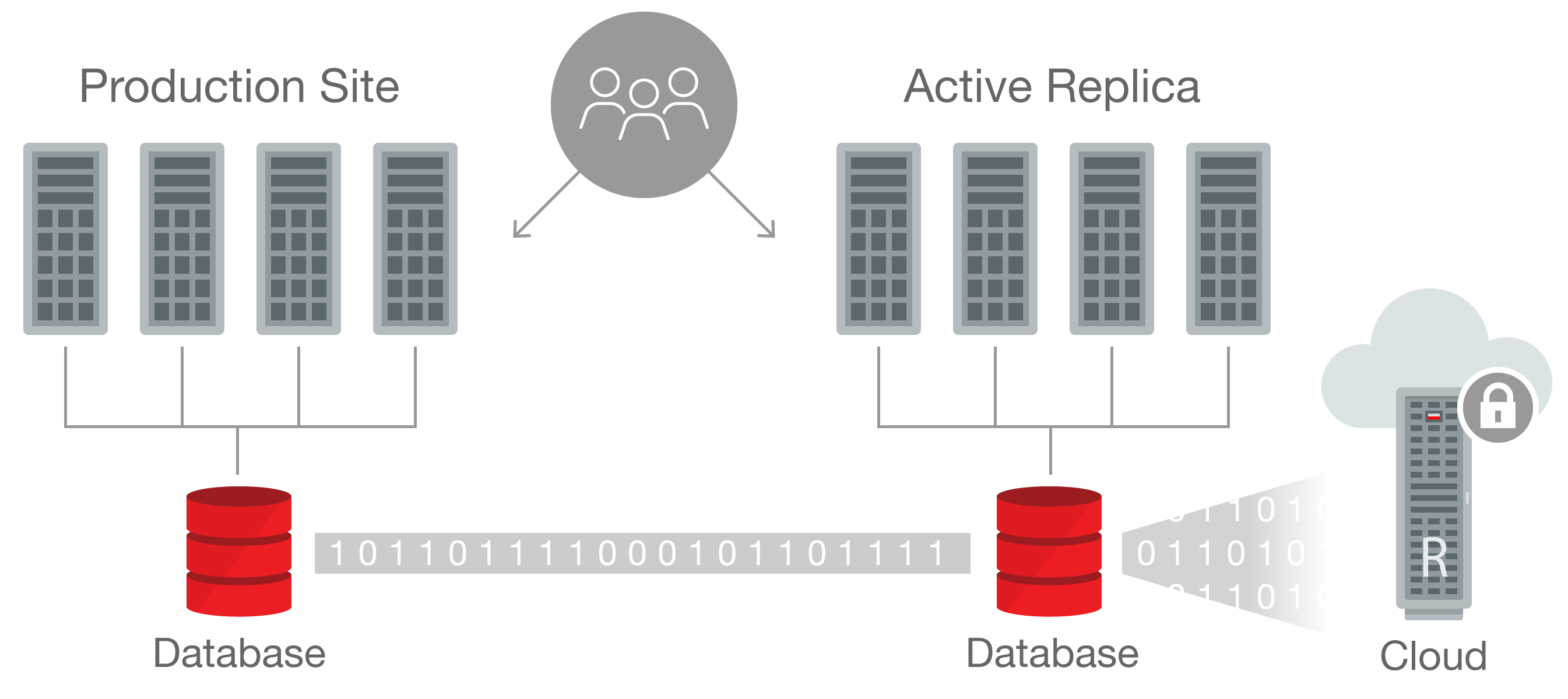
راهکارهابا توجه به حساسیت بالا در سرویس دهی سازمانها و همچنین روند رو به رشد الکترونیکی شدن تمامی فعالیتها در کشور، نیاز به سرویس دهی بدون وقفه پیش از پیش احساس شده و با توجه به اینکه از دسترس خارج شدن برخی از سرویسها حتی برای لحظاتی کوتاه خسارات جبران ناپذیری را به ارمغان می آورد پیاده سازی یک ساختار با رعایت تمامی حالتهای سرویس دهی بدون وقفه (High Availability) از نیاز اصلی و حیاتی تمامی ارگانها دولتی و خصوصی به شمار می رود.
"مرکز تحقیقات و توسعه فنآوری بهامد سازان" با مطالعه برروی سرویسها، نرم افزارها و تجهیزات گوناگون و همچنین بررسی و تحقیق برروی استانداردها و الگوریتمهای تکنولوژی High Availability جزء معدود شرکتهایی است که می تواند این خدمت را در بالاترین سطح ممکن و در تمامی لایه ها ارائه نماید. شرکت مهندسی "مرکز تحقیقات و توسعه فنآوری بهامد سازان" بر این باور است که رسیدن به سرویس دهی مطلوب، با رعایت کردن تمامی استانداردها و پیاده سازی تکنولوژیهای نوین امکان پذیر بوده و روند روز افزون تکنولوژی و همچنین پدید آمدن سرویسها و تجهیزات گوناگون نیز بر این امر حکایت دارد.
در ادامه به تعریف لایه ها مختلف سرویس دهی بدون وقفه (High Availability) می پردازیم و امیداوریم بتوانیم نگرش جدیدی از تکنولوژی را ایجاد نمائیم.
سرویس دهی بدون وقفه و یا سرویس دهی با دسترسی بالا (High Availability) تشریحی بر مدت زمان (طول زمان) عملیاتی بودن یک سیستم می باشد. از این رو زمانی که گفته می شود سرویسی به مدت ۹۹% در طول یک سال در دسترس بوده است، به این معنی است که در طول یک سال کامل (۸۷۶۰ ساعت = ۳۶۵*۲۴)، سرویس مورد نظر ۸۶۷۲،۴ ساعت عملیاتی بوده است.
یک سیستم با دسترسی بالا (High Availability)، به عملیاتی بودن یک سرویس در بیشترین زمان ممکن در طول یک زمان مشخص، اطلاق می شود.
تعریف معمول برای میزان در دسترس بودن (Availability)
مدت زمان در دسترس بودن = مدت زمان بالا بودن سیستم / مجموع زمان در یک بازه مشخص
این معادله عملا مفید نبوده و در صورتی که اگر (مجموع زمان در یک بازه مشخص – مدت زمان بالا نبودن سیستم) در محاسبه در نظر گرفته شود خروجی بدست آمده نسبتا دقیق می باشد.
مدت زمان در دسترس بودن = (مجموع زمان در یک بازه مشخص – مدت زمان بالا نبودن سیستم)/ مجموع زمان در یک بازه مشخص
از آنجایی که بدست آوردن متوسط مدت زمان بالا نبودن سیستم، دقت بیشتری نسبت به مدت زمان بالا بودن سیستم دارد، از این رو محاسبه انجام شده خروجی دقیق تری دارد.
سه اصل مهم در مهندسی یک سیستم با دسترسی بالا (Availability) شامل مواردی چون:
- حذف آسیب پذیری از یک نقطه (Single Point Of Failure) که به معنی اضافه کردن افزونگی به سیستم در جهت جلوگیری از کار افتان کل سیستم در ازاء خرابی یک بخش می باشد.
- در سیستمهایی که به صورت موازی فعالیت می کنند، در صورت بروز مشکل در یک بخش، بخشهای دیگر نیز تحت شعاع قرار می گیرند که در مهندسی High availability توجه به این امر نیز از اهمیت بالایی برخوردار می باشد.
- شناسایی خطا و یا آسیب پذیری در زمان وقوع. اگر چه رعایت کردن موارد بالا موجب می شود که کاربران کمتر تحت و شعاع آسیب پذیریها و خطاهای سیستم قرارگیرند، تعمیر و نگهداری این ساختار نیز از اهمیت بسیار بالایی برخوردار است.
استفاده از تکنولوژیهای روز، قابل اعتماد بودن یک سیستم را به میزان قابل توجهی افزایش می دهد. به عنوان مثال سازمانهای حساس و مراکز داده، پیاده سازی یک سیستم برای سرویس دهی بدون وقفه (High availability) و پیگیری فعالیتها و خرابی های روزانه، از اهمیت بسیار بالایی برخوردار می باشد.
از دسترس خارج کردن یک سیستم به صورت زمان بندی شده و یا برنامه ریزی نشده
به صورت کلی از دسترس خارج شدن زمان بندی شده در نتیجه تعمیر و نگهداری یک سیستم صورت می پذیرد. از دسترس خارج شدن زمان بندی شده، شامل مواردی چون بروز رسانی نرم افزار سیستم و یا تغییر تنظیمات بوده که برای اعمال مستلزم Restart کردن سیستم می باشد.
عموما از دسترس خارج شدن زمان بندی شده به دلایل منطقی و یا مدیریت رخدادها صورت می پذیرد. از دسترس خارج شدن زمان بندی نشده معمولا به دلایل رخدادهای فیزیکی مانند آسیب پذیریهای سخت افزاری و یا نرم افزاری و یا اتفاقات غیر متعارف صورت می پذیرد. به عنوان مثال، این موارد شامل مشکلات برقی و یا از کار افتان اجزایی مانند RAM و CPU و یا حتی بالارفتن درجه حرارت تجهیزات و در نتیجه آن خاموش شدن منطقی و یا فیزیکی ارتباطات شبکه، نقص امنیتی و یا دلایل گوناگونی چون از کار افتان سیستم عاملها، نرم افزارها و مواردی از این قبیل می باشد.
برخی از سازمانها مدت زمان از دسترس خارج شدن برنامه ریزی شده را در محاسبه میزان در دسترس بودن در نظر نگرفته، با این تصور که از دسترس خارج شدن برنامه ریزی شده تاثیر چندانی برروی جامعه کاربران آنها نداشته است. با این نوع محاسبه این سازمانها می توانند مدعی بالاترین زمان در دسترس بودن سرویس خود بوده که این امر در دسترس بودن مداوم سرویس دهی را تحت شعاع خود قرار می دهد. ساختاری که به صورت صادقانه میزان در دسترس بودن خود را نمایش می دهد از ارزش بالاتری برخوردار بوده و این نوع نگرش باعث پیاده سازی طراحی های منحصر به فرد در جهت حذف آسیب پذیری از یک نقطه (Single Point Of Failure) گردیده و در نتیجه آن انجام تمامی موارد تعمیر و نگهداری سیستم مانند سخت افزار، نرم افزار، شبکه، سیستم عامل و به روز رسانی سرویسها در زمان بالا بودن سیستم و بدون هیچ گونه قطعی امکان پذیر می باشد.
محاسبه درصد مدت زمان در دسترس بودن
میزان در دسترس بودن معمولا بیانگر درصدی از سرویس دهی سیستم در یک بازه زمانی مشخص می باشد. جدول زیر نشانگر میزان مدت زمان در دسترس نبودن سرویس می باشد که محاسبه زمان در دسترس بودن (Availability) سیستم را امکان پذیر می سازد. جدول زیر میزان درصد در دسترس بودن یک سرویس را بر اساس میزان زمان در دسترس نبودن آن سرویس، در طول یک سال، هفته و یا ماه محاسبه می کند.
|
درصد میزان در دسترس بودن |
میزان در دسترس نبودن در یک هفته |
میزان در دسترس نبودن در یک ماه |
میزان در دسترس نبودن در یک سال |
|
۹۰% – یک نه |
۱۶٫۸ ساعت |
۷۲ ساعت |
۳۶٫۵ روز |
|
۹۵% |
۸٫۴ ساعت |
۳۶ ساعت |
۱۸٫۲۵ روز |
|
۹۷% |
۵٫۰۴ ساعت |
۲۱٫۶ ساعت |
۱۰٫۹۶ روز |
|
۹۸% |
۳٫۳۶ ساعت |
۱۴٫۴ ساعت |
۷٫۳۰ روز |
|
۹۹% – دو نه |
۱٫۶۸ ساعت |
۷٫۲۰ساعت |
۳٫۶۵ روز |
|
۹۹٫۵% |
۵۰٫۴ دقیقه |
۳٫۶۰ ساعت |
۱٫۸۳ ساعت |
|
۹۹٫۸% |
۲۰٫۱۶ دقیقه |
۸۶٫۲۳ دقیقه |
۱۷٫۵۲ ساعت |
|
%۹۹،۹ – سه نه |
۱۰٫۱ دقیقه |
۴۳٫۸ دقیقه |
۸٫۷۶ ساعت |
|
۹۹،۹۵% |
۵٫۰۴ دقیقه |
۲۱٫۵۶ دقیقه |
۴٫۳۸ ساعت |
|
۹۹،۹۹% – ۴ نه |
۱٫۰۱ دقیقه |
۴٫۳۸ دقیقه |
۵۲٫۵۶ دقیقه |
|
۹۹،۹۹۵% |
۳۰٫۲۴ ثانیه |
۲٫۱۶ دقیقه |
۲۶٫۲۸ دقیقه |
|
۹۹،۹۹۹% – ۵ نه |
۶٫۰۵ ثانیه |
۲۵٫۹ ثانیه |
۵٫۲۶ دقیقه |
|
۹۹،۹۹۹۹% – ۶ نه |
۶۰۴٫۸ میلی ثانیه |
۲٫۵۹ ثانیه |
۳۱٫۵ ثانیه |
|
۹۹،۹۹۹۹۹% – ۷ نه |
۶۰٫۴۸ میلی ثانیه |
۲۶۲٫۹۷ میلی ثانیه |
۳٫۱۵ ثانیه |
|
۹۹،۹۹۹۹۹۹% – ۸ نه |
۶٫۰۴۸ میلی ثانیه |
۲۶٫۲۹۷ میلی ثانیه |
۳۱۵٫۵۶۹ میلی ثانیه |
|
۹۹،۹۹۹۹۹۹۹% – ۹ نه |
۰٫۶۰۴۸ میلی ثانیه |
۲٫۶۲۹۷ میلی ثانیه |
۳۱٫۵۵۶۹ میلی ثانیه |
نشان دادن ارزش خاص در دسترس بودن، به میزان ارقام ۹ به کار رفته در مقیاس درصد آن می باشد. برای مثال وقتی گفته می شود که یک سرویس به میزان ۹۹،۹۹۹% در یک زمان مشخص در دسترس بوده به این معنی است که میزان در دسترس بودن آن درجه اعتبار ۵ عدد نه و یا کلاس پنج می باشد. به طور معمول این نوع مقیاس در ارتباطات Mainframe ها و عملیات های وسیع مورد استفاده قرار می گیرد. Uptime و Availability از جهاتی شبیه به هم می باشند در صورتی که تفاوتهایی زیادی با یکدیگر دارند. به عنوان مثال یک سیستم می تواند آماده به سرویس باشد اما این سرویس در دسترس نباشد به مانند مشکلاتی شبیه به قطعی شبکه امکان سرویس دهی وجود نداشته باشد و همین امر به صورت برعکس نیز امکان پذیر می باشد. اما با توجه به این که از دسترس خارج شدن سرویس به هر دلیلی سرویس دهی را دچار مشکل می کند از این رو، این دو کلمه می توانند از جهاتی معانی مشابه داشته باشند.
به طور معمول در محاسبات مربوط به ارزیابی میزان در دسترس بودن یک سرویس (Availability) توسط "مرکز تحقیقات و توسعه فنآوری بهامد سازان"، از تعداد ۹ها به دلیل مشکل قراردادن آن در فرمول استفاده نمی شود. اغلب در دسترس نبودن یک سیستم به صورت یک احتمال و یا در طی یک سال مطرح می شود. میزان در دسترس بودن سرویس با مقیاس ۹های بکار رفته در آن معمولاً در اسناد تجاری مشاهده می گردد.
استفاده از تعداد ۹ها در نشان دادن میزان در دسترس بودن، در واقع نمایش درستی از واقعیت عدم در دسترس بودن سیستم را در زمانهای مختلف ندارد.
طراحی ساختار با میزان دسترسی بالا (High Availability)
به صورت اشتباه اینطور تصور می شود که جهت طراحی ساختاری با دسترسی بالا (High Available) باید مؤلفه های بیشتری به ساختار اضافه نمود، در صورتی که سیستم های پیچیده به صورت بالقوه دارای نقاط آسیب پذیر بیشتری می باشند و همچنین در پیاده سازی آنها به صورت کاملاً درست نیز احتمال بروز خطا وجود دارد. در واقع بیشتر آنالیز های صورت گرفته بر این تئوری تأکید دارد که ساختارهایی با دسترسی بالا (High Available) باید به معماری ساده توجه زیادی داشته باشد. اما باید به این موضوع توجه داشت که در عین حفظ سادگی در طراحی، همواره ساختار باید قابلیت دریافت به روز رسانی امنیتی و ارتقاء را در حوزه های مختلف، دارا باشد.
یکی از معیارهای طراحی پیشرفته و سطح بالا بروز رسانی و ارتقاء ساختار بدون بروز وقفه و خطا در سرویس دهی می باشد، همچنین باتوجه به اینکه معمول ترین علت بروز وقفه در سرویس دهی خطای انسانی می باشد طراحی ساختار های High Available باید به گونه ای باشد که کمترین نیاز به نیروی انسانی جهت بازگرداندن عملکرد در سیستم های پیچیده را داشته باشد.
افزونگی(Redundancy) جهت پیاده سازی میزان در دسترس بودن (Availability) در لایه های بالای طراحی استفاده می شود، افزونگی نیازمند شناسایی خطاهای احتمالی در لایه های مختلف و جلوگیری از به وجود آمدن آن ها می باشد. افزونگی در دو نوع Active و Passive وجود دارد.
افزونگی در حالت Passive در حالتی پیاده سازی می گردد که علاوه بر سرویس دهی بدون وقفه (High Availability) ساختار، ظرفیت کافی جهت جلوگیری از کاهش کارآیی در مواقع بروز خطا در یک قسمت را نیز داشته باشد. به عنوان یک مثال ساده یک قایق را با دو موتور و پروانه مجزا در نظر بگیرید که در صورت خرابی یک موتور، قایق با روشن شدن موتور دوم به حرکت خود با همان سرعت قبلی ادامه می دهد، با این شرط که قایق با یک موتور نیز از همان کارآیی لازم برخوردار باشد.
افزونگی در حالت Active به طور معمول در سیستم های پیچیده تر طراحی می گردد که علاوه بر سرویس دهی بدون وقفه (High Availability) در ساختار، از کاهش کارآیی نیز جلوگیری می نماید، به این صورت که تعدادی مؤلفه یکسان ( تجهیزات، سرور، برنامه و …. ) در طراحی استفاده می گردند که ساختار توانایی شناسایی خطا و تغییر تنظیمات جهت از سرویس خارج کردن نقطه خطا را دارا باشد. این ویژگی در سیستم های محاسباتی پیچیده و به هم وابسته استفاده می گردد.
یک طراحی کامل بدون قطع شدن سرویس (Zero Downtime) به این معنی است که نشان بدهد که زمان بین بروز خطا و قطع شدن سرویس به صورت قابل توجهی به زمان قطعی های برنامه ریزی شده جهت نگهداری، ارتقاء و پایان زمان سرویس نزدیک شود. به صورتی که تنها علت قطع شدن سرویس موارد برنامه ریزی شده باشد. لازمه عدم قطع شدن سرویس (Zero Downtime) نیاز به حجم عظیمی از افزونگی در لایه های مختلف را دارا می باشد.
اندازه گیری و کنترل خطا در ساختارهایی که افزونگی در آنها پیاده سازی نشده است در رسیدن به استانداردهای High Availability کمک شایانی می نماید. وقتی سیستم اندازه گیری خطا هشدار بروز خطا را نمایش می دهد عملیات تعمیر و یا نگهداری با یک Down-time بسیار کوتاه انجام می شود. بروز خطا فقط اگر در زمان های بسیار حساس اتفاق بیافتد باعث بروز مشکل برای ساختار می گردد.
مدل سازی و شبیه سازی جهت ارزیابی و اعتبار سنجی طراحی صورت پذیرفته کاربرهای فراوانی داشته و از خروجی های آن می توان ارزیابی حالت های مختلف طراحی را نام برد. در گام اول بعد از شبیه سازی کل سیستم طراحی شده با حذف یکی از مؤلفه ها، آزمایش انجام می شود. شبیه سازی افزونگی با شاخص N-X وارد عمل می شود، به طوری N اشاره دارد به تعداد مؤلفه هایی که برای افزونگی استفاده شده است و X تعداد مؤلفه هایی که جهت آزمایش حذف شده اند. N-1 به این معنی می باشد که کارآیی سیستم در حالتی که یکی از مؤلفه ها از سرویس خارج گردد آزمایش می گردد و همینطور در مورد N-2 از سرویس خارج شدن همزمان دو مؤلفه بررسی می گردد.
علل از دسترس خارج شدن سرویس
طبق ارزیابی و نظرسنجی های صورت گرفته از متخصصان در حوزه های دانشگاهی در خصوص مؤثرترین عوامل بر وقفه در سرویس دهی، اکثریت آنها علت آن را عدم رعایت استاندارها (Best Practice) اشاره نموده اند :
- کنترل کلیه مؤلفه های موثر
- ملزومات و تهیه تجهیزات مناسب
- نحوه عملکرد تمامی اجراء
- پیشگیری از بروز خطا در شبکه
- پیشگری از بروز خطا در برنامه ها
- پیشگیری از بروز وقفه در سرویس های خارج از شبکه
- محیط فیزیکی
- افزونگی در لایه شبکه
- راهکارهای اصولی پشتیبان گیری
- فرآیندهای پشتیبان گیری
- فضای فیزیکی نگهداری از تجهیزات
- افزونگی در ساختار
- افزونگی در لایه تجهیزات ذخیره سازی